Self-supervision for semantic occupancy estimation is appealing as it removes the labour-intensive manual annotation, thus allowing one to scale to larger autonomous driving datasets. Superquadrics offer an expressive shape family very suitable for this task, yet their deployment in a self-supervised setting has been hindered by the lack of efficient rendering methods to bridge the 3D scene representation and 2D training pseudo-labels. To address this, we introduce SuperQuadricOcc, the first self-supervised occupancy model to leverage superquadrics for scene representation. To overcome the rendering limitation, we propose a real-time volume renderer that preserves the fidelity of the superquadric shape during rendering. It relies on spatial superquadric–voxel indexing, restricting each ray sample to query only nearby superquadrics, thereby greatly reducing memory usage and computational cost. Using drastically fewer primitives than previous Gaussian-based methods, SuperQuadricOcc achieves state-of-the-art performance on the Occ3D-nuScenes dataset, while running at real-time inference speeds with substantially reduced memory footprint.
To begin, the transformer network refines superquadric means \( S_M \) and features \( S_F \), which are eventually transformed into full primitives for rendering. In SuperQuadricOcc-Render, following preliminary construction, we iterate over each ray sample \( r_j \), and query the spatial indexing tensors \( \mathbf{V}_{sq} \), \( \mathbf{V}_{n} \), \( \mathbf{V}_{f} \) to obtain the list of superquadrics \( \mathcal{Q}(v_{r_j}) \). We then compute the ray sample values \( \alpha_{r_j} \), \( \mathbf{s}_{r_j} \), and perform alpha compositing to produce the final semantic render \( \hat{S} \) and depth render \( \hat{D} \). During evaluation, superquadrics \( \mathcal{S} \) are voxelized.
For semantic occupancy estimation, SuperQuadricOcc produces coherent predictions largely due to the use of superquadrics, which enable a more efficient scene representation. The model accurately detects both nearby and distant objects through temporal flow, addressing the bias toward regions close to the camera that affected previous methods. Furthermore, it delivers these predictions at a real-time speed of 21 FPS.
For 2D depth and semantic estimation, SuperQuadricOcc coupled with SQOcc-R produces accurate renderings. Since supervision occurs in 2D space, the method remains particularly accurate in dense scenes containing many vehicles and other objects. SQOcc-R delivers these renders at 58 FPS across all six cameras.
On the Occ3D-nuScenes dataset, SuperQuadricOcc achieves state-of-the-art mIoU, surpassing previous methods based on voxel or Gaussian scene representations. Furthermore, the superquadric representation enables real-time inference with low memory usage of just 0.70 GB, more than doubling FPS while halving memory usage compared to prior methods. For the RayIoU metric, we again achieve state-of-the-art results, which is highlighted in the paper.
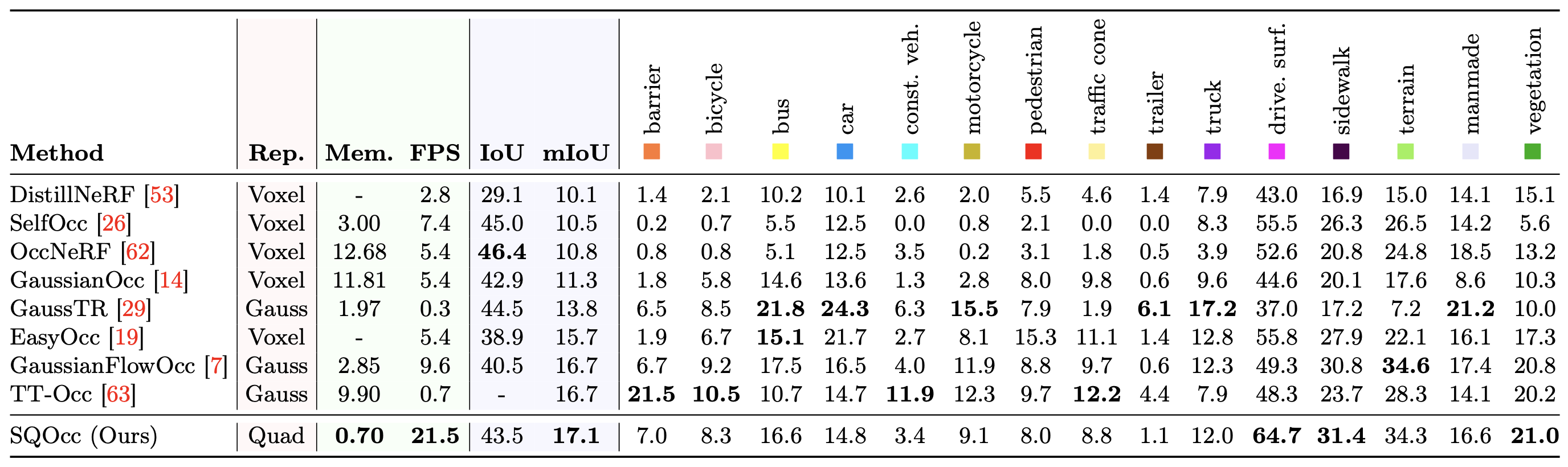
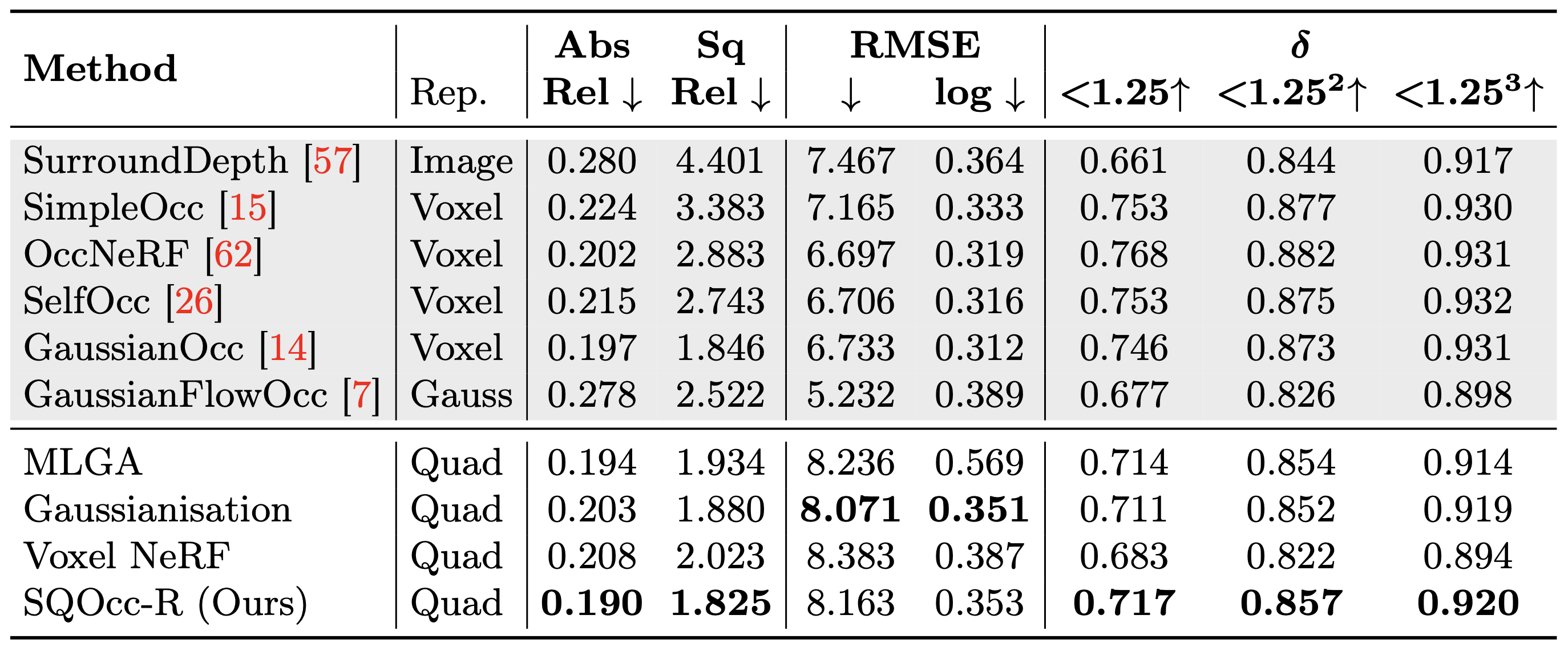
For depth estimation, we compare our novel rendering method, SQOcc-R, against three other superquadric rendering approaches as well as existing depth estimation models. SQOcc-R outperforms the other superquadric renderers due to the accuracy of volume rendering, which avoids lossy approximations of the superquadric shape. Furthermore, our method achieves state-of-the-art results on the Abs Rel and Sq Rel metrics across all compared methods, highlighting the effectiveness of superquadrics for scene representation and downstream tasks.
@article{hayes2025superquadricocc,
title={SuperQuadricOcc: Multi-Layer Gaussian Approximation of Superquadrics for Real-Time Self-Supervised Occupancy
Estimation},
author={Hayes, Seamie and Mohandas, Reenu and Brophy, Tim and Boulch, Alexandre and Sistu, Ganesh and Eising, Ciaran},
journal={arXiv preprint arXiv:2511.17361},
year={2025}
}